collaborative filtering recommendation engine implementation in python
Collaborative Filtering

In the introduction post of recommendation engine, we have seen the need of recommendation engine in real life as well as the importance of recommendation engine in online and finally we have discussed 3 methods of recommendation engine. They are:
1) Collaborative filtering
2) Content-based filtering
3) Hybrid Recommendation Systems
So today we are going to implement the collaborative filtering way of recommendation engine, before that I want to explain some key things about recommendation engine which was missed in Introduction to recommendation engine post.
Today learning Topics:
1) what is the Long tail phenomenon in recommendation engine ?
2) The basic idea about Collaborative filtering ?
3) Understanding Collaborative filtering approach with friends movie recommendation engine ?
4) Implementing Collaborative filtering approach of recommendation engine ?
what is the Long tail phenomenon in recommendation engine ?
Usage of Recommendation engine become popular in last 10 to 20 years. The reason behind this is we changed from a state of scarcity to abundance state. Don’t be frighten about this two words scarcity and abundance. Coming paragraph I will make you clear why I have used those words in popularity of recommendation engine.
Scarcity to Abundance:

Let’s understand scarcity to abundance with bookstores. Imagine a physical books store like crossword with thousands of books. we can see almost all popular books in books store shells, but shop shells are limited,to increasing number of shells, the retailer needs more space for this retailer need to spend some huge amount of money. This is the reason why we are missing some many good books which are less popular and finally we are only getting popular books.
On the other hand, if we see online web books stores, we have unlimited shells with unlimited shelf space, so we can get almost all books apart from popular or unpopular. This is because of web enables near-zero cost dissemination of information about products ( books,news articles, mobiles ,etc ). This new zero cost dissemination of information in web gives rise to a phenomenon called as “Long Tail” phenomenon.
Long Tail phenomenon:
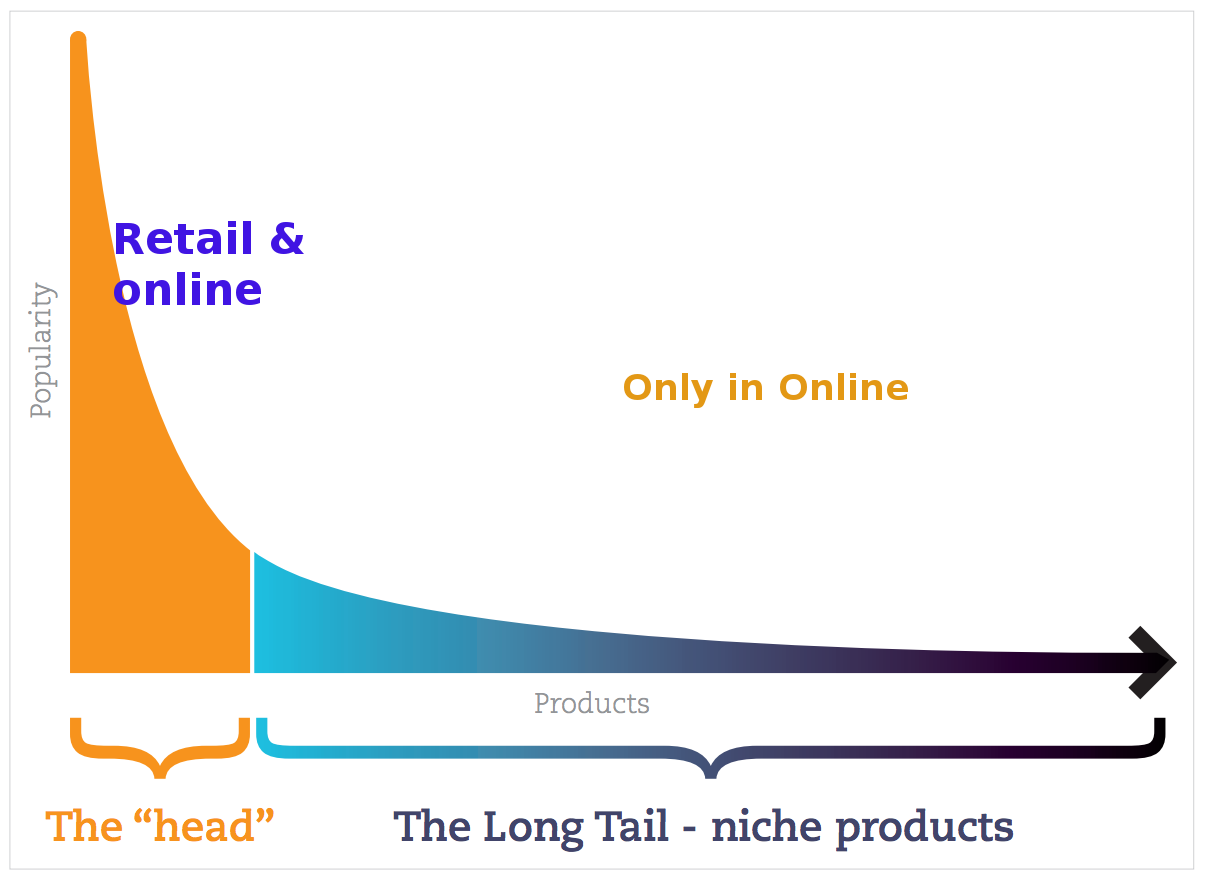
The above graph clearly represents the Long Tail phenomenon. On X – axis we have products with popularity (most popular ranked products will be at the left side and less popular ranked product will be going to right side). Here popularity means the number of times a product purchased or the number of times a product was viewed. On Y-axis it was genuine popularity means how many times products was purchased or viewed in an interval of time like one week or one month. If you see the graph at top Y – axis the orange color curve was just far away from the actual Y- axis this means they are very few popular products.
Coming to curve behavior Initially it has very stiff fall and if we move towards the right as the product rank become greater on X – axis, products popularity falls very stiffly and at a certain point this popularity fall less and less stiffly and it doesn’t reach X – axis .
The interesting things are products right side to the cutoff point was very very less popular and hardly they was purchased once or twice in a week or month. So these type of product we don’t get in physical retailer store because storing these fewer popular items is the waste of money so good business retailer don’t think to store them anymore. So popular product can be stored in physical retailers as well as we can get them in online too ,In the case of graph left
So popular product can be stored in physical retailers as well as we can get them in online too ,In the case of graph left side to the cutoff point which is Head part is the combination of the both physical retailer store and online store. Coming to the right side of the cutoff point which is less popular, so we can only get them in Online.
So this tail part to the right side of the cutoff point for the less popular product is called Long Tail. If you see the area under the curve of the Long tail we can notice there were some many good products which are less popular. Finding them is a harder task to the user in online so there is need of a system which can recommend these good products which are unpopular to user by considering some metrics. This system is nothing but recommendation system.
Basic idea about Collaborative filtering :
collaborative filtering algorithm usually works by searching a large group of people and finds a smaller set with tastes similar to the user. It looks at other things ,they like and combines then to create a ranked list of suggestions. Finally, shows the suggestion to the user. For the better understanding of collaborative filtering let’s think about our own friend’s movie recommendation system.
Collaborative filtering approach with friends movie recommendation engine:

Let’s understand collaborative filtering approach by friends movie recommendations engine. To explain friend’s movie recommendations engine I want to share my own story about this.
Like most of the people, I do love to watch movies in weekends. Generally, there were so many movies on my hard disk and it’s hard to select one movie from that. That’s the reason why when I want to watch a movie I will search for some of my friends who’s movie’s taste is similar to me and I will ask them to recommend a movie which I may like ( haven’t seen by me but seen by them ). They will recommend me a movie which they like and which I was never seen. it may be happened to you also.
This means to implement your own movie recommendation engine by considering your friends as a set of group people. Something you have learned over time by observing whether they usually like the same things as you. So you gonna select a group of your friends and you have to find someone who is more similar to you. Then you can expect movie recommendation from your friend. Applying this scenario of techniques to implement a recommendation engine is called as collaborative filtering.
Hope I have clear the idea about Collaborative filtering. So Let’s wet our hands by implementing collaborative filtering in Python programming language.
Implementing Collaborative filtering approach of recommendation engine :
Dataset for implementing collaborative filtering recommendation engine:
To implement collaborative filtering first we need data set having rated preferences ( how likely the people in data set like some set of items). So I am taking this data set from one of my favorite book Collective Intelligence book which was written by Toby Segaran.
First I am storing this data set to a Python Dictionary. For a huge data set, we generally store this preferences in Databases.
File name : recommendation_data.py
#!/usr/bin/env python
# Collabrative Filtering data set taken from Collective Intelligence book.
dataset={
'Lisa Rose': {
'Lady in the Water': 2.5,
'Snakes on a Plane': 3.5,
'Just My Luck': 3.0,
'Superman Returns': 3.5,
'You, Me and Dupree': 2.5,
'The Night Listener': 3.0},
'Gene Seymour': {'Lady in the Water': 3.0,
'Snakes on a Plane': 3.5,
'Just My Luck': 1.5,
'Superman Returns': 5.0,
'The Night Listener': 3.0,
'You, Me and Dupree': 3.5},
'Michael Phillips': {'Lady in the Water': 2.5,
'Snakes on a Plane': 3.0,
'Superman Returns': 3.5,
'The Night Listener': 4.0},
'Claudia Puig': {'Snakes on a Plane': 3.5,
'Just My Luck': 3.0,
'The Night Listener': 4.5,
'Superman Returns': 4.0,
'You, Me and Dupree': 2.5},
'Mick LaSalle': {'Lady in the Water': 3.0,
'Snakes on a Plane': 4.0,
'Just My Luck': 2.0,
'Superman Returns': 3.0,
'The Night Listener': 3.0,
'You, Me and Dupree': 2.0},
'Jack Matthews': {'Lady in the Water': 3.0,
'Snakes on a Plane': 4.0,
'The Night Listener': 3.0,
'Superman Returns': 5.0,
'You, Me and Dupree': 3.5},
'Toby': {'Snakes on a Plane':4.5,
'You, Me and Dupree':1.0,
'Superman Returns':4.0}}
Now we are ready with the data set. So let’s start implementing recommendation engine. create a new file with name collaborative_filtering.py be careful you created this file in the same directory where you created recommendation_data.py file. First, let’s import our recommendation dataset to collaborative_filtering.py file and let’s try whether we are getting data properly or not by answering the below questions.
1) What was the rating for Lady in the Water by Lisa Rose and Michael Phillips ?
2) Movie rating of Jack Matthews ?
File name : collaborative_filtering.py
#!/usr/bin/env python
# Implementation of collaborative filtering recommendation engine
from recommendation_data import dataset
print "Lisa Rose rating on Lady in the water: {}n".format(dataset['Lisa Rose']['Lady in the Water'])
print "Michael Phillips rating on Lady in the water: {}n".format(dataset['Michael Phillips']['Lady in the Water'])
print '**************Jack Matthews ratings**************'
print dataset['Jack Matthews']
Script Output:
Lisa Rose rating on Lady in the water: 2.5
Michael Phillips rating on Lady in the water: 2.5
**************Jack Matthews ratings**************
{'Lady in the Water': 3.0, 'Snakes on a Plane': 4.0, 'You, Me and Dupree': 3.5, 'Superman Returns': 5.0, 'The Night Listener': 3.0}
[Finished in 0.1s]
After getting data. we need to find the similar people by comparing each person with every other person this by calculating the similarity score between them. To know more about similarity you can view similarity score post. So Let’s write a function to find the similarity between two persons.
Similar Persons:
First, let use Euclidean distance to find similarity between two people. To do that we need to write a euclidean distance measured function Let’s add this function in collaborative_filtering.py and let’s find the Euclidean distance between Lisa Rose and Jack Matthews. Before that let’s remember Euclidean distance formula.
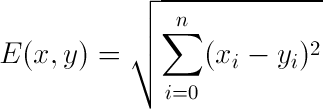
Euclidean distance is the most common use of distance. In most cases when people say about distance, they will refer to Euclidean distance. Euclidean distance is also known as simply distance. When data is dense or continuous , this is the best proximity measure. The Euclidean distance between two points is the length of the path connecting them.This distance between two points is given by the Pythagorean theorem.
#!/usr/bin/env python
# Implementation of collaborative filtering recommendation engine
from recommendation_data import dataset
from math import sqrt
def similarity_score(person1,person2):
# Returns ratio Euclidean distance score of person1 and person2
both_viewed = {} # To get both rated items by person1 and person2
for item in dataset[person1]:
if item in dataset[person2]:
both_viewed[item] = 1
# Conditions to check they both have an common rating items
if len(both_viewed) == 0:
return 0
# Finding Euclidean distance
sum_of_eclidean_distance = []
for item in dataset[person1]:
if item in dataset[person2]:
sum_of_eclidean_distance.append(pow(dataset[person1][item] - dataset[person2][item],2))
sum_of_eclidean_distance = sum(sum_of_eclidean_distance)
return 1/(1+sqrt(sum_of_eclidean_distance))
print similarity_score('Lisa Rose','Jack Matthews')
Source Output:
0.340542426583 [Finished in 0.0s]
This means the Euclidean distance score of Lisa Rose and Jack Matthews is 0.34054
Code Explanation:
Line 3-4:
- Imported recommendation data set and imported sqrt function.
Line 6-28:
- similarity_score function we are taking two parameters as person1 and person2
- The first thing we need to do is whether the person1 and person2 rating any common items. we doing this in line 12 to 14.
- Once we find the both_viewed we are checking the length of the both_viewed. If it zero there is no need to find similarity score why because it will zero.
- Then we find the Euclidean distance sum value by considering the items which were rated by both person1 and person2.
- Then we return the inverted value of euclidean distance. The reason behind using inverted euclidean distance is generally euclidean distance returns the distance between the two users. If the distance between two users is fewer means they are more similar but we need high value for the people who are similar so this can be done by adding 1 to euclidean distance ( so you don’t get a division by zero error) and inverting it.
Do you think the approach we used here is the good one to find the similarity between two users? Let’s consider an example to get the clear idea about is this good approach to find similarity between two users. Suppose we have two users X and Y. If X feels it’s good movie he will rate 4 for it, if he feels it’s an average movie he will rate 2 and finally if he feel it’s not a good movie he will rate 1. In the same way, Y will rate 5 for a good movie, 4 for an average move and 3 for worst movie.

If we calculated the similarity between both users it will somewhat similar but we are missing one great point here According to Euclidean distance if we consider a movie which rated by both X and Y. Suppose X-rated as 4 and Y rated as 4 then euclidean distance formulas give both X and Y are more similar, but this movie is good one for user X and an average movie for Y. So if we use Euclidean distance our approach will be wrong. So we have to use some other approach to find similarity between two users. This approach is Pearson Correlation.
Pearson Correlation:
Pearson Correlation Score:
A slightly more sophisticated way to determine the similarity between people’s interests is to use a Pearson correlation coefficient. The correlation coefficient is a measure of how well two sets of data fit on a straight line. The formula for this is more complicated that the Euclidean distance score, but it tends to give better results in situations where the data isn’t well normalized like our present data set.
Implementation for the Pearson correlation score first finds the items rated by both users. It then calculates the sums and the sum of the squares of the ratings for the both users and calculates the sum of the products of their ratings. Finally, it uses these results to calculate the Pearson correlation coefficient.Unlike the distance metric, this formula is not intuitive, but it does tell you how much the variables change together divided by the product of how much they alter individually.
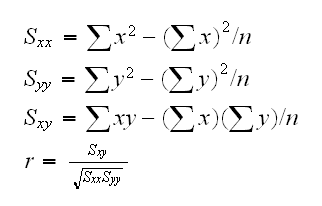
Let’s create this function in the same collaborative_filtering.py file.
# Implementation of collaborative filtering recommendataion engine
from recommendataion_data import dataset
from math import sqrt
def similarity_score(person1,person2):
# Returns ratio Euclidean distance score of person1 and person2
both_viewed = {} # To get both rated items by person1 and person2
for item in dataset[person1]:
if item in dataset[person2]:
both_viewed[item] = 1
# Conditions to check they both have an common rating items
if len(both_viewed) == 0:
return 0
# Finding Euclidean distance
sum_of_eclidean_distance = []
for item in dataset[person1]:
if item in dataset[person2]:
sum_of_eclidean_distance.append(pow(dataset[person1][item] - dataset[person2][item],2))
sum_of_eclidean_distance = sum(sum_of_eclidean_distance)
return 1/(1+sqrt(sum_of_eclidean_distance))
def pearson_correlation(person1,person2):
# To get both rated items
both_rated = {}
for item in dataset[person1]:
if item in dataset[person2]:
both_rated[item] = 1
number_of_ratings = len(both_rated)
# Checking for number of ratings in common
if number_of_ratings == 0:
return 0
# Add up all the preferences of each user
person1_preferences_sum = sum([dataset[person1][item] for item in both_rated])
person2_preferences_sum = sum([dataset[person2][item] for item in both_rated])
# Sum up the squares of preferences of each user
person1_square_preferences_sum = sum([pow(dataset[person1][item],2) for item in both_rated])
person2_square_preferences_sum = sum([pow(dataset[person2][item],2) for item in both_rated])
# Sum up the product value of both preferences for each item
product_sum_of_both_users = sum([dataset[person1][item] * dataset[person2][item] for item in both_rated])
# Calculate the pearson score
numerator_value = product_sum_of_both_users - (person1_preferences_sum*person2_preferences_sum/number_of_ratings)
denominator_value = sqrt((person1_square_preferences_sum - pow(person1_preferences_sum,2)/number_of_ratings) * (person2_square_preferences_sum -pow(person2_preferences_sum,2)/number_of_ratings))
if denominator_value == 0:
return 0
else:
r = numerator_value/denominator_value
return r
print pearson_correlation('Lisa Rose','Gene Seymour')
Script Output:
0.396059017191 [Finished in 0.0s]
Generally, this pearson_correlation function returns a value between -1 to 1 . A value 1 means both users are having the same taste in all most all cases.
Ranking similar users for a user:
Now that we have functions for comparing two people, we can create a function that scores everyone against a given person and finds the closest matches. Let’s add this function to collaborative_filtering.py file to get an ordered list of people with similar tastes to the specified person.
def most_similar_users(person,number_of_users):
# returns the number_of_users (similar persons) for a given specific person.
scores = [(pearson_correlation(person,other_person),other_person) for other_person in dataset if other_person != person ]
# Sort the similar persons so that highest scores person will appear at the first
scores.sort()
scores.reverse()
return scores[0:number_of_users]
print most_similar_users('Lisa Rose',3)
Script Output:
[(0.9912407071619299, 'Toby'), (0.7470178808339965, 'Jack Matthews'), (0.5940885257860044, 'Mick LaSalle')] [Finished in 0.0s]
What we have done now is we just look at the person who is the most similar persons to him and Now we have to recommend some movie to that person. But that would be too permissive. Such an approach could accidentally turn up reviewers who haven’t rated some of the movies that particular person like. it could also return a reviewer who strangely like a movie that got bad reviews from all the other person returned by most_similar_persons function.
To solve these issues, you need to score the items by producing a weighted score that ranks the users. Take the votes of all other persons and multiply how similar they are to a particular person by the score they gave to each move.
Below image shows how we have to do that.
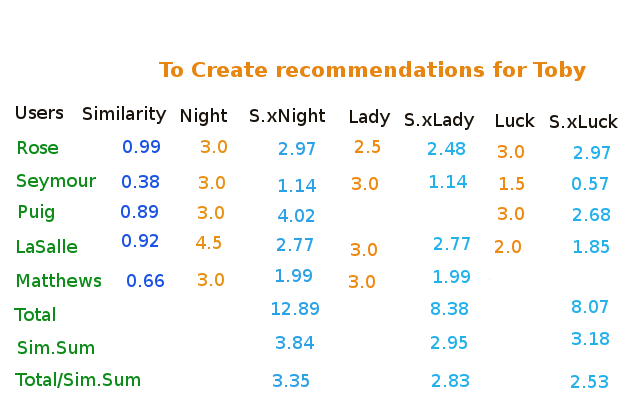
This image shows the correlation scores for each person and the ratings they gave for three movies The Night Listener, Lady in the Water, and Just My Luck that Toby hasn’t rated. The Columns beginning with S.x give the similarity multiplied by the rating,so a person who is similar to Toby will contribute more to the overall score than a person who is different from Toby. The Total row shows the sum of all these numbers.
We could just use the totals to calculate the rankings, but then a movie reviewed by more people would have a big advantage. To correct for this you need to divide by the sum of all the similarities for persons that reviewed that movie (the Sim.Sum row in the table) because The Night Listener was reviewed by everyone, it’s total is divided by the average of similarities. Lady in the water ,however , was not reviewed by Puig, The last row shows the results of this division.
Let’s implement that now.
def user_reommendations(person):
# Gets recommendations for a person by using a weighted average of every other user's rankings
totals = {}
simSums = {}
rankings_list =[]
for other in dataset:
# don't compare me to myself
if other == person:
continue
sim = pearson_correlation(person,other)
# ignore scores of zero or lower
if sim <=0:
continue
for item in dataset[other]:
# only score movies i haven't seen yet
if item not in dataset[person] or dataset[person][item] == 0:
# Similrity * score
totals.setdefault(item,0)
totals[item] += dataset[other][item]* sim
# sum of similarities
simSums.setdefault(item,0)
simSums[item]+= sim
# Create the normalized list
rankings = [(total/simSums[item],item) for item,total in totals.items()]
rankings.sort()
rankings.reverse()
# returns the recommended items
recommendataions_list = [recommend_item for score,recommend_item in rankings]
return recommendataions_list
print "Recommendations for Toby"
print user_reommendations('Toby')
Script Output:
Recommendations for Toby ['The Night Listener', 'Lady in the Water', 'Just My Luck'] [Finished in 0.0s]
We have done the Recommendation engine, just change any other persons and check recommended items.
To get total code you can clone our Github project :
https://github.com/saimadhu-polamuri/CollaborativeFiltering
All codes of dataaspirant blog can clone from the below-GitHub link:
https://github.com/saimadhu-polamuri/DataAspirant_codes
Reference Book:
Follow us:
FACEBOOK| QUORA |TWITTER| REDDIT | FLIPBOARD |LINKEDIN | MEDIUM| GITHUB
I hope you liked today’s post. If you have any questions then feel free to comment below or want me to write on one specific topic then do tell it to me in the comments below.
Want to share your experience or opinions you can say.





Useful indeed.
Hi Sasmita,
Thanks for your compliment.
Happy learning.
I got the answers. we need to find the sum of similarity of users which have rated that specific movies. No need to explain..
HI SAIMADHU!
HOPE U R FINE. WAITING FOR YOUR NEXT ARTICLES ON CONTENT BASED AND HYBRID RECOMMENDATION SYSTEM. It would be really helpful please do it
Hi Rozi Khan,
Thanks for suggesting the hybrid recommendations system topic, we will try to write an article on this specific topic.
Thanks and happy learning!
Hi SAIMADHU!
Hope u r fine. Waiting for your next articles on content based and Hybrid recommendation system.
Hi Rozi Khan,
Thanks for suggesting the hybrid recommendations system topic, we will try to write an article on this specific topic.
Thanks and happy learning!
Hi Dear, well explained and very helpful. I guess its user-user collaborative filtering?
Can u please write an article on item-item collaborative filtering. Thanks
Hi Rozi Khan,
Thanks for your compliment 🙂
Will try to come up with the article which explains the collaborative filtering concepts.
Please come up with context base and hybrid recommendations system
Hi Rozi Khan,
Thanks for suggesting the hybrid recommendations system topic, we will try to write an article on this specific topic.
Thanks and happy learning!
Hi,
I have implemented this with a dataset of 1000 records.
To calculate all similarities between all users it seems to be very slow?
Do you also have performance issues with this?
Thanks for the work!
Tobias
Hi Tobias,
Yes for more number of records it takes time to calculate the similarities.
Hi Saimadhu, It was a detailed post with crystal clear explanation, expecting a similar post on Hybrid recommendation.
Hi Soumyaansh,
Thanks for your compliment. 🙂
thanku much frnd …. it helped our grp a lot ..
Hi Dhananjaya,
I am glad that it helped you.
hi saimadhu, I run your code on the amazon review dataset, but the user do not rate for the same product and the pearson relation is always 0. Hence it wont recommend any item. Is there any remedy on that.
Hi Sachin,
If two users don’t have any common rated products pearson will always returns the value Zero. As we don’t have an common rated items between the users. Any how i will try to find way to get out of this conditions.
Thanks ,
Saimadhu
Excellent! But how would you evaluate your model? How would you know whether a ranking list of recommendation movies are suitable or not?
Great work. Keep it coming!
Thanks Al Krinker
what about using Jaccard similarity in this case?
If we use jaccard similarity in this case it will find similarity by considering two user rated movie or not. i won’t consider about the ratings. so we will miss judge the similarity between two users. That’s why we don’t use jaccard similarity.
Hi Saimadhu,
Amazingly explained example with step by step approach to Recommender system! I must say it is the simplified ever blog on RS I have come across, so nicely explained the fundamentals !!!
As I work in DS field, I understand the importance of conceptual understanding of techniques and there are very very few who have made things simple to understand for learners. You have hit the nail.
I have become fan of your writing, Saimadhu.
Keep it up! Can’t wait to read your next post on content based, hybrid filter RS examples.
Regards,
Pravin Bhosale
Thanks for your compliment pravin bhosale. i will try to write content based recommendation post by this month end.
Hi, bro, can you make some posts on how to implement content-based recommendation and hybrid recommendation with python? Thanks!
Sure.
Next post will be on Content-based recommendation implementation.
Hi, it’s very clear, thanks a lot!
Excellent..!