Linear Regression Implementation in Python
Linear regression implementation in python
In this post I gonna wet your hands with coding part too, Before we drive further. let me show what type of examples we gonna solve today.
1) Predicting house price for ZooZoo.

- ZooZoo gonna buy new house, so we have to find how much it will cost a particular house.
2) Predicting which Television Show will have more viewers for next week

The Flash and Arrow are my favorite Television ( Tv ) shows. i want to find which Tv show will get more viewers in upcoming week. Frankly i am so excited to know which show will get more viewers.
3) Replacing missing values using linear Regression
You have to solve this problem i will explain every thing you have to do. so please try to solve this problem.
So let’s drive into coding part
I believe you have installed all the required packages which i specified in my previous post. If not please take some time and install all the packages in this post python packages for datamining. It would better once your go through Linear Regression post.
1) Predicting cost price of a house for ZooZoo.

ZooZoo have the following data set
| No. | square_feet | price |
|---|---|---|
| 1 | 150 | 6450 |
| 2 | 200 | 7450 |
| 3 | 250 | 8450 |
| 4 | 300 | 9450 |
| 5 | 350 | 11450 |
| 6 | 400 | 15450 |
| 7 | 600 | 18450 |
About data set:
- Square feet is the Area of house.
- Price is the corresponding cost of that house.
Steps to Follow :
- As we learn linear regression we know that we have to find linear line for this data so that we can get θ0 and θ1.
- As you remember our hypothesis equation looks like this
![Image [7]](https://dataaspirant.com/wp-content/uploads/2014/09/image-7.png)
where:
- hθ(x) is nothing but the value price(which we are going to predicate ) for particular square_feet ( means price is a linear function of square_feet)
- θ0 is a constant
- θ1 is the regression coefficient
As we clear what we have to do, let’s start coding.
STEP – 1 :
- First open your favorite text editor and name it as predict_house_price.py.
- The below packages we gonna use in our program ,so copy them in your predict_house_price.py file.
# Required Packages import matplotlib.pyplot as plt import numpy as np import pandas as pd from sklearn import datasets, linear_model
- Just run your code once. if your program is error free then most of the job was done. If you facing any errors , this means you missed some packages so please go to this packages page
- Install all the packages in that blog post and run your code once again . This time most probably you will never face any problem.
- Means your program is error free now so we can go to STEP – 2.
STEP – 2
- I stored our data set in to a csv file with name input_data.csv
- So let’s write a function to get our data into X values ( square_feet ) Y values (Price)
# Function to get data
def get_data(file_name):
data = pd.read_csv(file_name)
x_parameter = []
y_parameter = []
for single_square_feet ,single_price_value in zip(data['square_feet'],data['price']):
x_parameter.append([float(single_square_feet)])
y_parameter.append(float(single_price_value))
return x_parameter,y_parameter
Line 3:
Reading csv data to pandas DataFrame.
Line 6-9:
Converting pandas dataframe data to x_parameter and y_parameter data returning them
So let’s print our x_parameters and y_parameters
x,y = get_data('input_data.csv')
print x
print y
Script Output
[[150.0], [200.0], [250.0], [300.0], [350.0], [400.0], [600.0]] [6450.0, 7450.0, 8450.0, 9450.0, 11450.0, 15450.0, 18450.0] [Finished in 0.7s]
Step – 3
we converted data to X_parameters and Y_parameter so let’s fit our X_parameters and Y_parameters to Linear Regression model
So we gonna write a function which will take x_parameters ,y_parameter and the value you gonna predict as input and return the θ0 ,θ1 and predicted value
# Function for Fitting data to Linear model
def linear_model_main(X_parameters,Y_parameters,predict_value):
# Create linear regression object
regr = linear_model.LinearRegression()
regr.fit(X_parameters, Y_parameters)
predict_outcome = regr.predict(predict_value)
predictions = {}
predictions['intercept'] = regr.intercept_
predictions['coefficient'] = regr.coef_
predictions['predicted_value'] = predict_outcome
return predictions
Line 5-6:
First we are creating an linear model and the training it with our X_parameters and Y_parameters
Line 8-12:
we are creating one dictionary with name predictions and storing θ0 ,θ1 and predicted values. and returning predictions dictionary as an output.
So let’s call our function with predicting value as 700
x,y = get_data('input_data.csv')
predict_value = 700
result = linear_model_main(x,y,predict_value)
print "Intercept value " , result['intercept']
print "coefficient" , result['coefficient']
print "Predicted value: ",result['predicted_value']
Script Output:
Intercept value 1771.80851064 coefficient [ 28.77659574] Predicted value: [ 21915.42553191] [Finished in 0.7s]
Here Intercept value is nothing but θ0 value and coefficient value is nothing but θ1 value.
We got the predicted values as 21915.4255 means we done our job of predicting the house price.
For checking purpose we have to see how our data fit to linear regression.So we have to write a function which takes X_parameters and Y_parameters as input and show the linear line fitting for our data.
# Function to show the resutls of linear fit model
def show_linear_line(X_parameters,Y_parameters):
# Create linear regression object
regr = linear_model.LinearRegression()
regr.fit(X_parameters, Y_parameters)
plt.scatter(X_parameters,Y_parameters,color='blue')
plt.plot(X_parameters,regr.predict(X_parameters),color='red',linewidth=4)
plt.xticks(())
plt.yticks(())
plt.show()
So let call our show_linear_line Function
show_linear_line(X,Y)
Script Output:
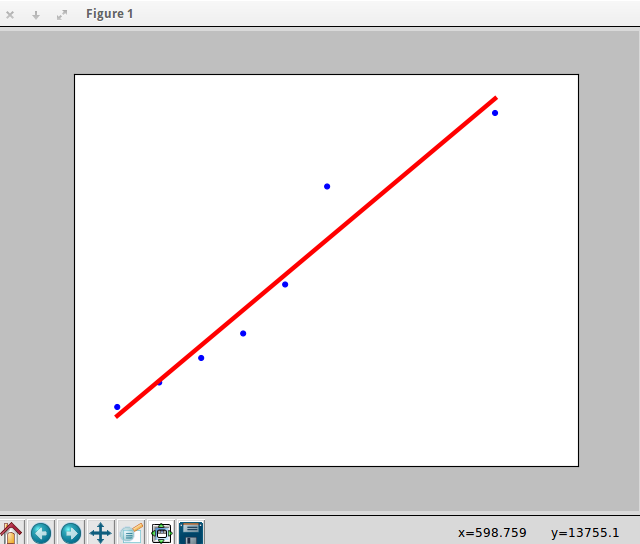
2) Predicting which Television Show will have more viewers
![]()
About The FLASH Tv show:

The Flash is an American television series developed by writer/producers Greg Berlanti, Andrew Kreisberg and Geoff Johns, airing on The CW. It is based on the DC Comics character Flash (Barry Allen), a costumed superhero crime-fighter with the power to move at superhuman speeds, who was created by Robert Kanigher, John Broome andCarmine Infantino. It is a spin-off from Arrow, existing in the same universe. The pilot for the series was written by Berlanti, Kreisberg and Johns, and directed by David Nutter. The series premiered in North America on October 7, 2014, where the pilot became the most watched telecast for The CW.
About Arrow Tv Show:
![]()
Arrow is an American television series developed by writer/producers Greg Berlanti, Marc Guggenheim, and Andrew Kreisberg. It is based on the DC Comics characterGreen Arrow, a costumed crime-fighter created by Mort Weisinger and George Papp. It premiered in North America on The CW on October 10, 2012, with international broadcasting taking place in late 2012. Primarily filmed in Vancouver, British Columbia, Canada, the series follows billionaire playboy Oliver Queen, portrayed by Stephen Amell, who, after five years of being stranded on a hostile island, returns home to fight crime and corruption as a secret vigilante whose weapon of choice is a bow and arrow. Unlike in the comic books, Queen does not initially go by the alias “Green Arrow”.
As both of these are my best-loved Tv show when ever i am watching these shows i feel myself which show have more viewers and i am so interested to guess which show will have more viewers.
So lets write a program which guess( predict ) which Tv Show will have more viewers.
For free drive of our program we need some dataset which having both shows viewers for each episode. Luckly i got this data from Wikipidia and prepared an csv file. It’s looks like this.
| flash_episode | flash_us_viewers | arrow_episode | arrow_us_viewers | |
|---|---|---|---|---|
| 1 | 4.83 | 1 | 2.84 | |
| 2 | 4.27 | 2 | 2.32 | |
| 3 | 3.59 | 3 | 2.55 | |
| 4 | 3.53 | 4 | 2.49 | |
| 5 | 3.46 | 5 | 2.73 | |
| 6 | 3.73 | 6 | 2.6 | |
| 7 | 3.47 | 7 | 2.64 | |
| 8 | 4.34 | 8 | 3.92 | |
| 9 | 4.66 | 9 | 3.06 |
About data set:
Us viewers ( millions )
Step by steps to solving this problem:
- First we have to convert our data to x_parameters and y_parameters but here we have two x_parameters and y_parameters so lets’s name them as flash_x_parameter, flash_y_parameter, arrow_x_parameter , arrow_y_parameter.
- Then we have to fit our data to two different linear regression models first for flash and other for arrow.
- Then we have to predict the number of viewers for next episode for both of the Tv shows.
- Then we can compare the results and we can guess which Tv Shows will have more viewers.
Let’s drive to code this interesting problem.
Step-1
We have to import our packages
# Required Packages import csv import sys import matplotlib.pyplot as plt import numpy as np import pandas as pd from sklearn import datasets, linear_model
Step-2
Converting our data to flash_x_parameter,flash_y_parameter,arrow_x_parameter ,arrow_y_parameter so lets write a function which will take our data set as input and returns lash_x_parameter,flash_y_parameter,arrow_x_parameter ,arrow_y_parameter values.
# Function to get data
def get_data(file_name):
data = pd.read_csv(file_name)
flash_x_parameter = []
flash_y_parameter = []
arrow_x_parameter = []
arrow_y_parameter = []
for x1,y1,x2,y2 in zip(data['flash_episode_number'],data['flash_us_viewers'],
data['arrow_episode_number'],data['arrow_us_viewers']):
flash_x_parameter.append([float(x1)])
flash_y_parameter.append(float(y1))
arrow_x_parameter.append([float(x2)])
arrow_y_parameter.append(float(y2))
return flash_x_parameter,flash_y_parameter,arrow_x_parameter,arrow_y_parameter
now we have flash_x_parameters,flash_y_parameters,arrow_x_parameters,arrow_y_parameters. so let’s write a function which will take these above parameters as input and gives an output as which show will have more views.
# Function to know which Tv show will have more viewers
def more_viewers(x1,y1,x2,y2):
regr1 = linear_model.LinearRegression()
regr1.fit(x1, y1)
predicted_value1 = regr1.predict(9)
print predicted_value1
regr2 = linear_model.LinearRegression()
regr2.fit(x2, y2)
predicted_value2 = regr2.predict(9)
if predicted_value1 > predicted_value2:
print "The Flash Tv Show will have more viewers for next week"
else:
print "Arrow Tv Show will have more viewers for next week"
So let’s write every thing in one file open your editor and name it as prediction.py and copy this total code into prediction.py file.
# Required Packages
import csv
import sys
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn import datasets, linear_model
# Function to get data
def get_data(file_name):
data = pd.read_csv(file_name)
flash_x_parameter = []
flash_y_parameter = []
arrow_x_parameter = []
arrow_y_parameter = []
for x1,y1,x2,y2 in zip(data['flash_episode_number'], data['flash_us_viewers'],
data['arrow_episode_number'],data['arrow_us_viewers']):
flash_x_parameter.append([float(x1)])
flash_y_parameter.append(float(y1))
arrow_x_parameter.append([float(x2)])
arrow_y_parameter.append(float(y2))
return flash_x_parameter,flash_y_parameter,arrow_x_parameter,arrow_y_parameter
# Function to know which Tv show will have more viewers
def more_viewers(x1,y1,x2,y2):
regr1 = linear_model.LinearRegression()
regr1.fit(x1, y1)
predicted_value1 = regr1.predict(9)
print predicted_value1
regr2 = linear_model.LinearRegression()
regr2.fit(x2, y2)
predicted_value2 = regr2.predict(9)
if predicted_value1 > predicted_value2:
print "The Flash Tv Show will have more viewers for next week"
else:
print "Arrow Tv Show will have more viewers for next week"
x1,y1,x2,y2 = get_data('input_data.csv')
# Call the function more_viewers to predict the more viewers television show
more_viewers(x1,y1,x2,y2)
Run this program and see which Tv show will have more viewers.
You can get all the complete codes of dataaspirant at dataaspirant data science codes
3) Replacing missing values using linear Regression
some times we have a situation where we have to do analysis on data which consists of missing values. Some people will remove these missing values and they continue analysis and some people replace them with min value or max value or mean value it’s good to replace missing value with mean value but so time it’s not the right way to replace missing with mean value so we can use linear regression to replace those missing value very effectively.
This approach goes some thing like this.
First we have find which column we gonna replace missing values and we have to find on which columns this missing values column values more depends on ,then we have to remove the missing value rows. Then consider missing values column as Y_parameters and consider the columns on which this missing values more depend as X_parameters and fit this data to Linear regression model . Now predict the missing values in missing values column by consider the columns on which this missing values column more depends.
Once all this process completed we will get data without any missing values so we are free to analysis data.
For practice i leave this problem to you so please kindly get some missing values data from online and solve this problem. Leave your comments once you completed .i so happy to view them.
Small personal note:
I want to share my personal experience with data mining. I remember in my introductory datamining classes The instructor starts slow and explains some interesting areas where we can apply datamining and some very basic concepts so i and my friends understand every thing and we show more interest towards datamining. Then suddenly the difficulty leave will sky rocket. This makes a lot of my friends in class feel like extremely frustrated and intimated by course and ultimately they left interest on datamining. So i want to avoid this thing in my blog posts. In my blog post i want to make thing more easygoing this would be possible only when i explain things with some interest examples moreover i want to make my blog viewers more comfortable learning without any boring so i am in that spirit which leads me towards use this examples.
Follow us:
FACEBOOK| QUORA |TWITTER| GOOGLE+ | LINKEDIN| REDDIT | FLIPBOARD | MEDIUM | GITHUB
I hope you like this post. If you have any questions then feel free to comment below. If you want me to write on one specific topic then do tell it to me in the comments below.





I am getting x is not defined while giving show_linear(x,y).
I got x and y values as output also got Intercept value 1771.80851064
coefficient [ 28.77659574]
Predicted value: [ 21915.42553191]
but while running show_linear(x,y) getting x is not defined
Hi Saimadhu,
Your post is very nice and more useful. I have one small suggestion for you that please make some formatting’s (Use indentation) in your code part. It will be more easy to understand soon. Thank you for your post 🙂
Hi Bhuvaneshwaran,
Thanks for your compliment. We were so happy for you suggestion too. Will update the code with proper indentation.
Hello Saimadhu
Can you please upload multiple linear regression code example as well .
Regards
Hi Abhishek,
Soon I will share you the multiple linear regression codes.
Thanks saimadhu
Eagerly waiting for those samples . Meanwhile awesome job with linear regression code example .
Hello saimadhu
sorry for bothering again but any luck with multiple linear regression code example
Hello, saimadhu. I make Guthub Repository for this article. Github Page for this Repository^ http://stepprogrammer.github.io/Data-Science/
New corrected URL is http://technodexx.github.io/Data-Science/
Thanks Igor Golov.
This blog is awesome idea, friend.
I have a working algorithm for linear regression, compiled on the materials of your blog. Algorithm works on Python version 2.7.x and 3.4.x
Look it here: http://pastebin.com/VxeUT5zW
Hello, A good implementation for regression analysis.. Thanks 🙂
Hi Nivedita,
Thanks for your complement.
I have a working algorithm for linear regression, compiled on the materials of your blog. The algorithm works on Python version 2.7.x and 3.4.x
Look it here: http://pastebin.com/VxeUT5zW
This blog is awesome idea, friend!
Thanks Igor
Don’t mention it, Saimadhu. By the way: R – square for your data equal 0.944668586035943 (94.46685860359429%) Not bad, as I understand it. ))
fantabulous ….!!!
Hi Manjal,
Thanks for your complement 🙂
Really enjoyed this post. Nice into and like what you did in section 3. I tend to use mean values for missing data, but using linear regresssion is pretty cool actually. Will do next time.
Also… some of the imports were unused in sample code, so I cleaned it up some. Here it is
# Required Packages
import matplotlib.pyplot as plt
import pandas as pd
from sklearn import linear_model
HI AI Krinker
Thanks for your compliment.
It’s remarkable in support of me to have a web site,
which is useful in favor of my knowledge. thanks admin
Thanks 🙂
You have solved regression for one variable what to do if 3 or more variables are present y=c1*x1+2*x2
It’s actually a great and useful piece of info. I’m glad that you shared this useful
information with us. Please stay us up to date like this.
Thanks for sharing.
Thank’s Linkemporor
Pretty portion of content. I just stumbled upon your weblog
and in accession capital to claim that I acquire in fact
enjoyed account your blog posts. Anyway I will be subscribing in your feeds or even I fulfillment you get right of entry to
consistently rapidly.
This tutorial is great! But i’m pretty new to this and i have a question:
predicted_value1 = regr1.predict(9)
what does the “9” represent in this line of code for example 2?
Hi Nosy Nittany thanks for asking about it actually we are predicting how many viewers will be for 9 episode that’s why we we are calling our predicted function with value 9.
Wonderful … Math is cool… 🙂
I just released an IPython Notebook with a more detailed introduction to linear regression in Python, and thought your readers might be interested! http://www.dataschool.io/linear-regression-in-python/
Sure kevin 🙂
Wow! Thank you so much. Waiting for logistic regression. Do you have more business examples as share?
Hi XiaoXiao Sam
Thank’s for your complement.
now i posting recommendations stuff, once it completed i will write a post on Logistic regression. Coming to your question i have some pretty good examples related to business soon i will explain with business examples.
Thank’s for your advice XiaoXial Sam
Brother your tutorial rocked. Expecting tutorial on logistic regression next time
Sure i am planing to do it
thank you for this blog. I wanted to start ML in python after octave, and this is the perfect way.
All the best. python is best option for ML
Traceback (most recent call last):
File “predict_house_price-2.py”, line 19, in
X,Y = get_data(‘input_data.csv’)
File “predict_house_price-2.py”, line 14, in get_data
for single_square_feet ,single_price_value in zip(data[‘square_feet’],data[‘price’]):
File “/usr/lib/python2.7/dist-packages/pandas/core/frame.py”, line 1658, in __getitem__
return self._getitem_column(key)
File “/usr/lib/python2.7/dist-packages/pandas/core/frame.py”, line 1665, in _getitem_column
return self._get_item_cache(key)
File “/usr/lib/python2.7/dist-packages/pandas/core/generic.py”, line 1005, in _get_item_cache
values = self._data.get(item)
File “/usr/lib/python2.7/dist-packages/pandas/core/internals.py”, line 2874, in get
_, block = self._find_block(item)
File “/usr/lib/python2.7/dist-packages/pandas/core/internals.py”, line 3186, in _find_block
self._check_have(item)
File “/usr/lib/python2.7/dist-packages/pandas/core/internals.py”, line 3193, in _check_have
raise KeyError(‘no item named %s’ % com.pprint_thing(item))
KeyError: u’no item named square_feet’
What happened ??