How Q learning can be used in reinforcement learning


Q learning in reinforcement learning
Reinforcement learning with Q learning
In the reinforcement learning implementation in r article, we discussed the basics of reinforcement learning. In the same article, we learned the key topics like the policy, reward, state, action with real-life examples.
The next favorite topic to learn when it comes to reinforcement learning is Q learning. So in this article, you are going learn how Q learning is used in Reinforcement learning.
Before we drive further. Lets quickly look at the table of contents of this article.
Table of contents:
- Reinforcement learning recap
- What is Q-learning
- Reinforcement learning with Q learning applications
- Drone delivery environment
- Enhancements in drone delivery systems
- Autonomous cars
- Enhancements in autonomous cars
- Conclusion
- Related courses
Reinforcement learning recap
Reinforcement learning (RL) is training agents to finish tasks. The mission of the programmer is to make the agent accomplish the goal.
Consider making a robot to learn how to open the door. Reinforcement learning utilized as a base from which the robot agent can learn to open the door from trial and error.
Reinforcement learning is where agents interact in an environment to maximize begotten rewards over time. Agent interaction with the environment happens in the following way:
An agent receives a state (s) from the environment and produces an action (a) in the same environment. With this action and state pair, the environment provides the agent a new state (s′) and a reward (r). A huge cumulative reward can be affected by discovering a mapping from states to actions.
That’s all for the quick recap of reinforcement learning. If you want to learn more about it, Do checkout introduction to reinforcement learning article.
If you want to learn more such concepts, you can consider Intellipaat’s data science course once.
What is Q-learning?
One approach to the above-discussed problem is called Q-learning. Where there is a direct mapping between state and action pairs (s, a) and value estimations (v).
This value estimation is in tune with the discounted expected reward over time from taking action (a) while in a state (s). Through Bellman equation, estimations of Q(s, a) will estimate for all possible state action pairs.
The property of optimal Q function’s property can iteratively update the Q value
Q[s,a] = r + γmaxa′Q(s′,a′)
The equation in essence means
Q[s,a] = immediate reward + discounted reward
Where:
r represents immediate reward, and γmaxa′ Q(s′, a′) represents discounted reward.
To estimate the importance of rewards in the future the discount factor(γ) will use. The agent will become pragmatic if the discount factor is 0. If the factor is 1 then it will try for greater reward in the future.
The action values simply diverge when the discount factor exceeds 1. If γ=1 where there is no terminal state or when the agent doesn’t go to 1 the environment histories will long infinitely and those utilities with additive, undiscounted rewards will usually be infinite.
In the case when the discount factor is lower than 1 then errors and instabilities will arise when the value function Q[s, a] is approximated with an artificial neural network. It can assume that when from discount factor ascends from lower value to higher value then there is accelerated learning.
Neural networks can be made to predict correct Q values, and expected values can be optimized to obtain a high cumulative reward. By using a universal function approximator like a neural network one can generalize Q-estimation to unseen states, allowing him to know Q-functions for arbitrarily large state spaces.
Reinforcement learning with Q learning applications
Drone delivery environment

Drone delivery a Q learning application
Q-learning which is like other traditional reinforcement learning learns from only a single reward signal and hence can pursue just a single goal at a time.
Consider we have to make the drone deliver to various locations in the city. In that case, also this goal-based reinforcement learning comes into play.
Assume agent needs a 5×5 grid position, and the delivery destination occupies another destination. The drone can move in 4 directions.
- UP
- DOWN
- LEFT
- RIGHT
The drone is rewarded with a point (+1) when it moves to a correct destination and makes a delivery. The above image portrays how precisely the agent is learning and acting as per that.
A simple state representation can be used here of 5×5 grid, of RBG pixels (75 values in total) to portray the environment. Due to the virtue of this arrangement, the learning process may reduce to minutes from hours. An episode can take 100 steps and agent, and delivery locations can randomize at the threshold of every episode.
Enhancements in drone delivery systems
A drone in the real world won’t be able to deliver packages without end. Its battery would eventually run out of time. It, therefore, needs to recharge at some point.
So, a battery recharging point can be set up for this purpose. To incentivize the drone to recharge navigating to the drone can be rewarded with some value. But what if the drone endlessly navigates to and for from current point to recharging point? Apparently, battery status has to consider in the rewarding process.
The Q-learning algorithm if given proper time and tweaked with proper hyperparameter tuning that recharging is beneficial to accomplishing the task in the long term. Through this, the agent infers that if it recharges the battery in a timely fashion then it can deliver more packages in the long term.
This entails the drone agent to take a series of tasks that don’t have immediate reward but have a higher reward in the long run.
A reward signal of about +0.5 can provide for flying to the battery recharging point. If we want to make this idea practical then description can be made formal. The concept is known as direct future prediction (DFP).
Without including the battery function, the agent would generally map a state (s) to a Q-value estimate of Q(s, a). This action would fetch the agent a reward (r). But when we include the battery function then the scenario changes entirely.
New parameters like a set of measurements (m), goals (g) along with state (s) will be used to train the network to predict the future changes for each action (a) in measurements (f).
Battery charge and the number of packages delivered are the two measurements which we ought to consider. Unlike in standard Q learning which involves in predicting a value function, we can instead train our network to estimate the would change in battery. This can happen in deliveries at 1,2,4,8,16 steps into the future.
This can formulate the following equation:
f = < mT1-m0, mT2-m0…mTn-m0>
with T being the temporal offsets [1,2, 4, …etc]
There are no explicit rewards in this setup now. How well the goals and measurements align is what determines success.
This would translate to making the maximum deliveries and making sure that the battery gets charged when it gets low. Assume our agent was highly competent in predicting future measurements for each of these actions. In that case, we have just to make the action that optimized our interested measurements.
The goals which we want are what defines the measurements at a particular time.
More intricate goals
Using this model one can formulate complex goals than as we do more than just deal with single scalar value.
Let’s assume we have a measurement vector [battery, deliveries]. Take for instance we wanted to ignore charging the battery and focused only on making deliveries. Then the measurement vector would, in essence, be represented as [0,1].
If on the other hand, we wanted to prioritize charging the battery on top of making deliveries then the measurement vector would be [1,0]. As we have complete autonomy on changing and modifying the values we can change the measurement vector at any time. This comes as a huge benefit to the solution which we are trying to bring out.
We can design the drone agent in such a way that it is by default [0,1] where it means that it is making deliveries. Assume the battery falls below 25% then the drone agent’s goal can be changed from making deliveries to getting the battery charged. We can therefore dynamically alter the goal of the drone agent as per our requirements.
Our neural network is altered in various ways by this new formulation. Instead of providing only the state as the input we will also give the measurements and goal. The network will give as output the prediction tensor of the form [measurements x actions x offsets].
One can best choose actions that optimally satisfy the goals over time by considering the product of summation of predicted future changes and our goals.
a = gT * ∑p(s,m,g)
where ∑p(s,m,g) is the transpose of the goal vector and is the network’s output which is a summation of future timesteps.
To estimate the true measurement changes into the future. The drone agent can be trained with a simple regression loss:
Loss = ∑[P(s,m,g,a)−f(m)]2
Where P(s,m,g, a) is the output for the selected task of the network.
If the implementation completed successfully, then we have a drone agent that is poised in the making deliveries on time. We have to ensure that the agent accomplishes this while having a charged battery.
The flexibility to change the goal as and when required is the defining feature in this enhancement.
Autonomous cars
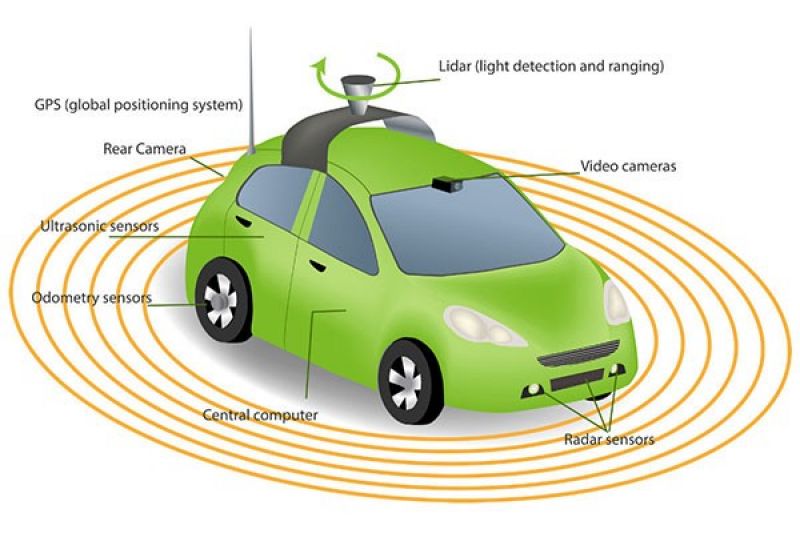
Autonomous cars | Image credit: racv.com.au
This is causing all the rave in the tech journals, scientific newsletters. Google made a blind person seated on the wheel of the driverless car as it traversed miles together and created a ruckus in the tech community.
Google’s Waymo is on a mission to make driverless commuting across safe and comfortable for people of all age groups. But why am I saying this in this article is the concept of Q learning can apply here as well.
In this environment, the agent (driverless car) can be used reach a particular destination. The area where the agent starts moving is the starting point, and the destination is the ending point.
The agent can steer front, left, right or can go reverse. The agent will be reward with (+1) for correctly driving to a particular location. Each episode will contain 100 meters. After the agent traverses the distance of 100 meters, the agent and delivery locations will be randomized freshly for each episode.
Enhancements in autonomous cars
A real-world driverless car can’t just go on driving from point to another without end. It needs to recharge as its electric battery would run out.
In traversing every episode(100 meters), the battery may reduce a bit. Running out of battery in the mid-road would essentially mean that agent will become useless. In contrast, a car with human driver can do something to rectify this. He can change the battery as and when needed manually.
But this advantage can’t be expected in driverless cars. When the agent doesn’t reach the destination due to being stranded on the road without being charged then it doesn’t get the reward for reaching the destination.
We, therefore, have to input the recharging stations also when we design the whole scenario to the agent. Due to this, the agent has to be made to go to the electric recharging station when the battery hits low.
If that is not the case then it can resume its course to reach the destination. The agent has to learn that recharging is essential to drive to the final destination in the long term. This means the driverless car agent has to snap out of its pragmatic goals of immediate reward and think of a higher reward in the future.
One can include a reward for recharging the battery but again what if the agent makes successive to and fro trips to the battery charging station to the path which leads to the destination.
In case of driverless cars, however, there are many more things to keep in mind. It is a well-known fact that road infrastructure is rarely up to the standards commonly. Often the lanes are not marked correctly. The white lines will misalign on the road. The bott dots(little plastic bumps) which will supposedly mark lanes won’t put correctly.
In that case, the sensor which embedded in the agent should be capable of detecting such an error in the lane. After correctly ascertaining the environment the agent should continue on its task of reaching the destination.
Conclusion
To refrain from indulging in bad reward engineering a more intuitive way of engineering can be used to structure the task to the agent. We have to design the agent with an explicit goal that can vary with the episode and the particular situation.
Then only can we expect the dynamic behaviors we want. In case of battery recharge, we can change the goal state to battery recharging point instead of the destination of delivery.
If we change the reward formulation this way, the neural networks can learn about the environment dynamics themselves.
Follow us:
FACEBOOK| QUORA |TWITTER| GOOGLE+ | LINKEDIN| REDDIT | FLIPBOARD | MEDIUM | GITHUB
I hope you like this post. If you have any questions, then feel free to comment below. If you want me to write on one particular topic, then do tell it to me in the comments below.




