Svm classifier, Introduction to support vector machine algorithm

vmSupport vector machine introduction
SVM Classifier Introduction
Hi, welcome to the another post on classification concepts. So far we have talked bout different classification concepts like logistic regression, knn classifier, decision trees .., etc. In this article, we were going to discuss support vector machine which is a supervised learning algorithm. Just to give why we were so interested to write about Svm as it is one of the powerful technique for Classification, Regression & Outlier detection with an intuitive model.
Before we drive into the concepts of support vector machine, let’s remember the backend heads of Svm classifier. Vapnik & Chervonenkis originally invented support vector machine. At that time, the algorithm was in early stages. Drawing hyperplanes only for linear classifier was possible.
Later in 1992 Vapnik, Boser & Guyon suggested a way for building a non-linear classifier. They suggested using kernel trick in SVM latest paper. Vapnik & Cortes published this paper in the year 1995
From then, Svm classifier treated as one of the dominant classification algorithms. In further sections of our article, we were going to discuss linear and non-linear classes. However, Svm is a supervised learning technique. When we have a dataset with features & class labels both then we can use Support Vector Machine. But if in our dataset do not have class labels or outputs of our feature set then it is considered as an unsupervised learning algorithm. In that case, we can use Support Vector Clustering.
Enough of the introduction to support vector machine algorithm. Let’s drive into the key concepts.
How Svm classifier Works?
For a dataset consisting of features set and labels set, an SVM classifier builds a model to predict classes for new examples. It assigns new example/data points to one of the classes. If there are only 2 classes then it can be called as a Binary SVM Classifier.
There are 2 kinds of SVM classifiers:
- Linear SVM Classifier
- Non-Linear SVM Classifier
Svm Linear Classifier:
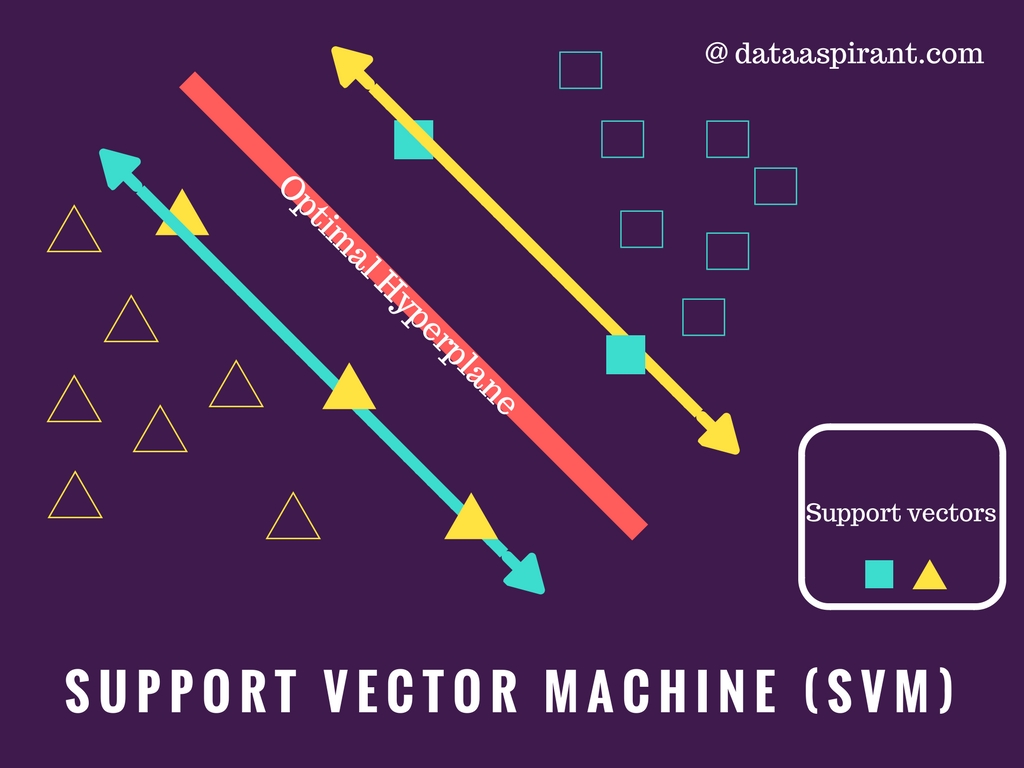
In the linear classifier model, we assumed that training examples plotted in space. These data points are expected to be separated by an apparent gap. It predicts a straight hyperplane dividing 2 classes. The primary focus while drawing the hyperplane is on maximizing the distance from hyperplane to the nearest data point of either class. The drawn hyperplane called as a maximum-margin hyperplane.
SVM Non-Linear Classifier:
In the real world, our dataset is generally dispersed up to some extent. To solve this problem separation of data into different classes on the basis of a straight linear hyperplane can’t be considered a good choice. For this Vapnik suggested creating Non-Linear Classifiers by applying the kernel trick to maximum-margin hyperplanes. In Non-Linear SVM Classification, data points plotted in a higher dimensional space.
Examples of SVM boundaries
In this section, we will learn about selecting best hyperplane for our classification. We will show data from 2 classes. The classes represented by triangle $latex \bigtriangleup$ and circle$latex \bigcirc$.
1. Case 1:Consider the case in Fig 2, with data from 2 different classes.Now, we wish to find the best hyperplane which can separate the two classes. Please check Fig 1. on the right to find which hyperplane best suit this use case.In SVM, we try to maximize the distance between hyperplane & nearest data point. This is known as margin. Since 1st decision boundary is maximizing the distance between classes on left and right. So, our maximum margin hyperplane will be “1st “. |
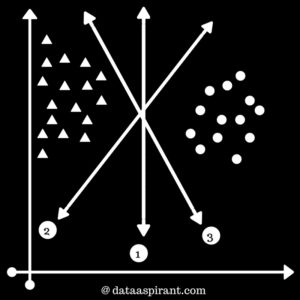 Fig 1 |
Case 2:Consider the case in Fig 2, with data from 2 different classes.Now, we wish to find the best hyperplane which can separate the two classes. As data of each class is distributed either on left or right. Our motive is to select hyperplane which can separate the classes with maximum margin. In this case, all the decision boundaries are separating classes but only 1st decision boundary is showing maximum margin between $latex \bigtriangleup$ & $latex \bigcirc $. |
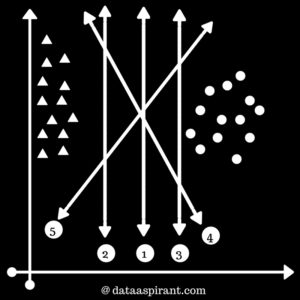 Fig 2 |
Case 3:Consider the case in Fig 3, with data from 2 Data is not evenly distributed on left and right. Some of the $latex \bigtriangleup $ are on right too. You may feel we can ignore the two data points above 3rd hyperplane but that would be incorrect. SVM tries to find out maximum margin hyperplane but gives first priority to correct classification. 2nd decision boundary is separating the data points similar to 1st boundary but here margin between boundary and data points is larger than the previous case. 3rd decision boundary is separating all $latex \bigtriangleup $ from all $latex \bigcirc $ classes. |
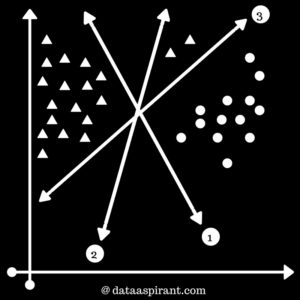 Figure 3 |
Case 4:Consider the figure 4, we will learn about outliers in SVM. We wish to find the best hyperplane which can separate the two classes. In the real world, you may find f ew values that correspond to extreme cases i.e, exceptions.These exceptions are known as Outliers. SVM have the capability to detect and ignore outliers.In the image, 2 $latex \bigtriangleup \text{‘s}$ are in between the group of $latex \bigcirc $. These $latex \bigtriangleup \text{‘s}$ are outliers. While selecting hyperplane, SVM will automatically ignore these $latex \bigtriangleup \text{‘s}$ and select best-performing hyperplane.1st & 2nd decision boundaries are separating classes but 1st decision boundary shows maximum margin in between boundary and support vectors. |
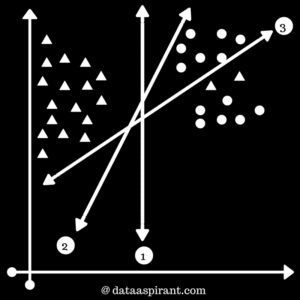 Figure 4 |
Case 5:We will learn about non-linear classifiers. Please check the figure 5 on right. It’s showing that data can’t be We can use different types of kernels like Radial Basis Function Kernel, Polynomial kernel etc. We have shown a decision boundary separating both the classes. This decision boundary resembles a parabola. |
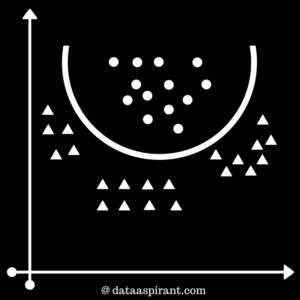 Figure 5 |
Linear Support Vector Machine Classifier
In Linear Classifier, A data point considered as a p-dimensional vector(list of p-numbers) and we separate points using (p-1) dimensional hyperplane. There can be many hyperplanes separating data in a linear order, but the best hyperplane is considered to be the one which maximizes the margin i.e., the distance between hyperplane and closest data point of either class.
The Maximum-margin hyperplane is determined by the data points that lie nearest to it. Since we have to maximize the distance between hyperplane and the data points. These data points which influences our hyperplane are known as support vectors.
Non-Linear Support Vector Machine Classifier
Vapnik proposed Non-Linear Classifiers in 1992. It often happens that our data points are not linearly separable in a p-dimensional(finite) space. To solve this, it was proposed to map p-dimensional space into a much higher dimensional space. We can draw customized/non-linear hyperplanes using Kernel trick.
Every kernel holds a non-linear kernel function.
This function helps to build a high dimensional feature space. There are many kernels that have been developed. Some standard kernels are:
- Polynomial (homogeneous) Kernel:

The polynomial kernel function can be represented by the above expression. Where k(xi, xj) is a kernel function, xi & xj are vectors of feature space and d is the degree of polynomial function.
- Polynomial(non-homogeneous) Kernel:
In the non-homogeneous kernel, a constant term is also added. The constant term “c” is also known as a free parameter. It influences the combination of features. x & y are vectors of feature space.
- Radial Basis Function Kernel:
It is also known as RBF kernel. It is one of the most popular kernels. For distance metric squared euclidean distance is used here. It is used to draw completely non-linear hyperplanes.
where x & x’ are vectors of feature space.is a free parameter. Selection of parameters is a critical choice. Using a typical value of the parameter can lead to overfitting our data.

Selecting the Svm Hyperplanes

Source: Wikipedia Support Vector Machine
Linearly Separable: For the data which can be separated linearly, we select two parallel hyperplanes that separate the two classes of data, so that distance between both the lines is maximum. The region b/w these two hyperplanes is known as “margin” & maximum margin hyperplane is the one that lies in the middle of them.
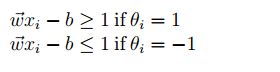
where 

For proper classification, we can build a combined equation:
![]()
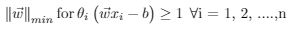
Non-Linearly Separable: To build classifier for non-linear data, we try to minimize
![{\displaystyle \left[{\frac {1}{n}}\sum _{i=1}^{n}\max \left(0,1-y_{i}({\vec {w}}\cdot {\vec {x}}_{i}-b)\right)\right]+\lambda \lVert {\vec {w}}\rVert ^{2},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/53b729df53f32c7fbf933b1b034a8e368037d9b5)
Here, max() method will be zero( 0 ), if xi is on the correct side of the margin. For data that is on opposite side of the margin, the function’s value is proportional to the distance from the margin.
where, 

Advantages of SVM Classifier:
- SVMs are effective when the number of features is quite large.
- It works effectively even if the number of features are greater than the number of samples.
- Non-Linear data can also be classified using customized hyperplanes built by using kernel trick.
- It is a robust model to solve prediction problems since it maximizes margin.
Disadvantages of SVM Classifier:
- The biggest limitation of Support Vector Machine is the choice of the kernel. The wrong choice of the kernel can lead to an increase in error percentage.
- With a greater number of samples, it starts giving poor performances.
- SVMs have good generalization performance but they can be extremely slow in the test phase.
- SVMs have high algorithmic complexity and extensive memory requirements due to the use of quadratic programming.
Support Vector Machine Libraries / Packages:
For implementing support vector machine on a dataset, we can use libraries. There are many libraries or packages available that can help us to implement SVM smoothly. We just need to call functions with parameters according to our need.
In Python, we can use libraries like sklearn. For classification, Sklearn provides functions like SVC, NuSVC & LinearSVC.
SVC() and NuSVC() methods are almost similar but with some difference in parameters. We pass values of kernel parameter, gamma and C parameter etc. By default kernel parameter uses “rbf” as its value but we can pass values like “poly”, “linear”, “sigmoid” or callable function.
LinearSVC() is an SVC for Classification that uses only linear kernel. In LinearSVC(), we don’t pass value of kernel, since it’s specifically for linear classification.
In R programming language, we can use packages like “e1071” or “caret”. For using a package, we need to install it first. For installing “e1071”, we can type install.packages(“e1071”) in console.
e1071 provides an SVM() method, it can be used for both regression and classification. SVM() method accepts data, gamma values and kernel etc.
SVM Applications:
SVMS are a byproduct of Neural Network. They are widely applied to pattern classification and regression problems. Here are some of its applications:
- Facial expression classification: SVMs can be used to classify facial expressions. It uses statistical models of shape and SVMs.
- Speech recognition: SVMs are used to accept keywords and reject non-keywords them and build a model to recognize speech.
- Handwritten digit recognition: Support vector classifiers can be applied to the recognition of isolated handwritten digits optically scanned.
- Text Categorization: In information retrieval and then categorization of data using labels can be done by SVM.
Reference Links:
[1] https://en.wikipedia.org/wiki/Support_vector_machine
[2] http://www.support-vector-machines.org/SVM_soft.html
[3] https://core.ac.uk/download/pdf/6302770.pdf
Follow us:
FACEBOOK| QUORA |TWITTER| GOOGLE+ | LINKEDIN| REDDIT | FLIPBOARD | MEDIUM | GITHUB
I hope you like this post. If you have any questions, then feel free to comment below. If you want me to write on one particular topic, then do tell it to me in the comments below.
Related Courses:
Do check out unlimited data science courses
| Title & links | Details | What You Will Learn |
Machine Learning A-Z: Hands-On Python & R In Data Science |
Course Overall Rating:: 4.6 |
|
Machine Learning: Classification |
Course Overall Rating:: 4.7 |
|
Practical Machine Learning |
Course Overall Rating:: 4.4 |
|




