KNN R, K-Nearest Neighbor implementation in R using caret package

knn classifier implementation with r caret package
Knn classifier implementation in R with caret package
In this article, we are going to build a Knn classifier using R programming language. We will use the R machine learning caret package to build our Knn classifier. In our previous article, we discussed the core concepts behind K-nearest neighbor algorithm. If you don’t have the basic understanding of Knn algorithm, it’s suggested to read our introduction to k-nearest neighbor article.
For Knn classifier implementation in R programming language using caret package, we are going to examine a wine dataset. Our motive is to predict the origin of the wine. As in our Knn implementation in R programming post, we built a Knn classifier in R from scratch, but that process is not a feasible solution while working on big datasets.
To work on big datasets, we can directly use some machine learning packages. Developer community of R programming language has built some great packages to make our work easier. The beauty of these packages is that they are well optimized and can handle maximum exceptions to make our job simple, we just need to call functions for implementing algorithms with the right parameters. For machine learning caret package is a nice package with proper documentation.
The principle behind KNN classifier (K-Nearest Neighbor) algorithm is to find K predefined number of training samples that are closest in the distance to a new point & predict a label for our new point using these samples.
Euclidean Distance
The most commonly used distance measure is Euclidean distance. The Euclidean distance is also known as simply distance. The usage of Euclidean distance measure is highly recommended when data is dense or continuous. Euclidean distance is the best proximity measure.
KNN classifier is also considered to be an instance based learning / non-generalizing algorithm. It stores records of training data in a multidimensional space. For each new sample & particular value of K, it recalculates Euclidean distances and predicts the target class. So, it does not create a generalized internal model.
Caret Package Installation
The R programming machine learning caret package( Classification And REgression Training) holds tons of functions that helps to build predictive models. It holds tools for data splitting, pre-processing, feature selection, tuning and supervised – unsupervised learning algorithms, etc. It is similar to sklearn library in python.
For using it, we first need to install it. Open R console and install it by typing:
install.packages("caret")
caret package provides us direct access to various functions for training our model with various machine learning algorithms like Knn, SVM, decision tree, linear regression, etc.
Knn implementation with caret package
Wine Recognition Data Set Description

Wine recognition with knn in R
For this experiment, wines were grown in the same region in Italy but derived from 3 different cultivars. The analysis determined the quantities of 13 constituents found in each of the three types of wines. We have a dataset with 13 attributes having continuous values and one attribute with class labels of wine origin.
Using the wine dataset our task is to build a model to recognize the origin of the wine. The original owners of this dataset are Forina, M. et al. , PARVUS, Institute of Pharmaceutical and Food Analysis and Technologies, Via Brigata Salerno, 16147 Genoa, Italy. This wine dataset is hosted as open data on UCI machine learning repository.
The 13 Attributes of the dataset are:
- Alcohol
- Malic acid
- Ash
- Alkalinity of ash
- Magnesium
- Total phenols
- Flavanoids
- Nonflavonoids phenols
- Proanthocyanins
- Color intensity
- Hue
- OD280/OD315 of diluted wines
- Proline
The attribute with the class label is at index 1. It consists of 3 values 1, 2 & 3. These class labels are going to be predicted by our KNN model.
Wine Recognition Problem Statement:
To model a classifier for classifying the origin of the wine. The classifier should predict whether the wine is from origin “1” or “2” or “3”.
Knn classifier implementation in R with Caret Package
R caret Library:
For implementing Knn in r, we only need to import caret package. As we mentioned above, it helps to perform various tasks to perform our machine learning work.
library(caret)
Data Import:
We are using wine dataset from UCI repository. For importing the data and manipulating it, we are going to use data frames. First of all, we need to download the dataset.
dataurl <- "https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data"
download.file(url = dataurl, destfile = "wine.data")
wine_df <- read.csv("wine.data", header = FALSE)
In dataurl vector, we are putting URL of our wine data. Using download.file() method, we can download the data file from URL. For downloading, URL of data and destination file name should be mentioned as the parameters of download.file() method. Here, our destfile parameter is set with value “wine.data”.
For importing data into an R data frame, we can use read.csv() method with parameters as a file name and whether our dataset consists o the 1st row with a header or not. If a header row exists then, the header should be set TRUE else header should set to FALSE.
For checking the structure of data frame we can call the function str over wine_df:
> str(wine_df) 'data.frame': 178 obs. of 14 variables: $ V1 : int 1 1 1 1 1 1 1 1 1 1 ... $ V2 : num 14.2 13.2 13.2 14.4 13.2 ... $ V3 : num 1.71 1.78 2.36 1.95 2.59 1.76 1.87 2.15 1.64 1.35 ... $ V4 : num 2.43 2.14 2.67 2.5 2.87 2.45 2.45 2.61 2.17 2.27 ... $ V5 : num 15.6 11.2 18.6 16.8 21 15.2 14.6 17.6 14 16 ... $ V6 : int 127 100 101 113 118 112 96 121 97 98 ... $ V7 : num 2.8 2.65 2.8 3.85 2.8 3.27 2.5 2.6 2.8 2.98 ... $ V8 : num 3.06 2.76 3.24 3.49 2.69 3.39 2.52 2.51 2.98 3.15 ... $ V9 : num 0.28 0.26 0.3 0.24 0.39 0.34 0.3 0.31 0.29 0.22 ... $ V10: num 2.29 1.28 2.81 2.18 1.82 1.97 1.98 1.25 1.98 1.85 ... $ V11: num 5.64 4.38 5.68 7.8 4.32 6.75 5.25 5.05 5.2 7.22 ... $ V12: num 1.04 1.05 1.03 0.86 1.04 1.05 1.02 1.06 1.08 1.01 ... $ V13: num 3.92 3.4 3.17 3.45 2.93 2.85 3.58 3.58 2.85 3.55 ... $ V14: int 1065 1050 1185 1480 735 1450 1290 1295 1045 1045 ...
It shows that our data consists of 178 observations and 14 columns. Value ranges of all attributes from V2-V14 are varying, so we will have to standardize the data before training our classifier.
Data Slicing
Data slicing is a step to split data into train and test set. Training data set can be used specifically for our model building. Test dataset should not be mixed up while building model. Even during standardization, we should not standardize our test set.
set.seed(3033) intrain <- createDataPartition(y = wine_df$V1, p= 0.7, list = FALSE) training <- wine_df[intrain,] testing <- wine_df[-intrain,]
The set.seed() method is used to make our work replicable. As we want our readers to learn concepts by coding these snippets. To make our answers replicable, we need to set a seed value. During partitioning of data, it splits randomly but if our readers will pass the same value in the set.seed() method. Then we both will get identical results.
The caret package provides a method createDataPartition() for partitioning our data into train and test set. We are passing 3 parameters. The “y” parameter takes the value of variable according to which data needs to be partitioned. In our case, target variable is at V1, so we are passing wine_df$V1 (wine data frame’s V1 column).
The “p” parameter holds a decimal value in the range of 0-1. It’s to show that percentage of the split. We are using p=0.7. It means that data split should be done in 70:30 ratio. The “list” parameter is for whether to return a list or matrix. We are passing FALSE for not returning a list. The createDataPartition() method is returning a matrix “intrain” with record’s indices.
By passing values of intrain, we are splitting training data and testing data.
The line training <- wine_df[intrain,] is for putting the data from data frame to training data. Remaining data is saved in the testing data frame, testing <- wine_df[-intrain,].
For checking the dimensions of our training data frame and testing data frame, we can use these:
> dim(training); dim(testing); [1] 125 14 [1] 53 14
Preprocessing & Training
Preprocessing is all about correcting the problems in data before building a machine learning model using that data. Problems can be of many types like missing values, attributes with a different range, etc.
To check whether our data contains missing values or not, we can use anyNA() method. Here, NA means Not Available.
> anyNA(wine_df) [1] FALSE
Since it’s returning FALSE, it means we don’t have any missing values.
Wine Dataset summarized details
For checking the summarized details of our data, we can use summary() method. It will give us a basic idea about our dataset’s attributes range.
> summary(wine_df)
V1 V2 V3 V4 V5 V6
Min. :1.000 Min. :11.03 Min. :0.740 Min. :1.360 Min. :10.60 Min. : 70.00
1st Qu.:1.000 1st Qu.:12.36 1st Qu.:1.603 1st Qu.:2.210 1st Qu.:17.20 1st Qu.: 88.00
Median :2.000 Median :13.05 Median :1.865 Median :2.360 Median :19.50 Median : 98.00
Mean :1.938 Mean :13.00 Mean :2.336 Mean :2.367 Mean :19.49 Mean : 99.74
3rd Qu.:3.000 3rd Qu.:13.68 3rd Qu.:3.083 3rd Qu.:2.558 3rd Qu.:21.50 3rd Qu.:107.00
Max. :3.000 Max. :14.83 Max. :5.800 Max. :3.230 Max. :30.00 Max. :162.00
V7 V8 V9 V10 V11 V12
Min. :0.980 Min. :0.340 Min. :0.1300 Min. :0.410 Min. : 1.280 Min. :0.4800
1st Qu.:1.742 1st Qu.:1.205 1st Qu.:0.2700 1st Qu.:1.250 1st Qu.: 3.220 1st Qu.:0.7825
Median :2.355 Median :2.135 Median :0.3400 Median :1.555 Median : 4.690 Median :0.9650
Mean :2.295 Mean :2.029 Mean :0.3619 Mean :1.591 Mean : 5.058 Mean :0.9574
3rd Qu.:2.800 3rd Qu.:2.875 3rd Qu.:0.4375 3rd Qu.:1.950 3rd Qu.: 6.200 3rd Qu.:1.1200
Max. :3.880 Max. :5.080 Max. :0.6600 Max. :3.580 Max. :13.000 Max. :1.7100
V13 V14
Min. :1.270 Min. : 278.0
1st Qu.:1.938 1st Qu.: 500.5
Median :2.780 Median : 673.5
Mean :2.612 Mean : 746.9
3rd Qu.:3.170 3rd Qu.: 985.0
Max. :4.000 Max. :1680.0
From above summary statistics, it shows us that all the attributes have a different range. So, we need to standardize our data. We can standardize data using caret’s preProcess() method.
Our target variable consists of 3 values 1, 2, 3. These should considered as categorical variables. To convert these to categorical variables, we can convert them to factors.
training[["V1"]] = factor(training[["V1"]])
The above line of code will convert training data frame’s “V1” column to factor variable.
Now, it’s time to train our model.
Training the Knn model
Caret package provides train() method for training our data for various algorithms. We just need to pass different parameter values for different algorithms. Before train() method, we will first use trainControl() method. It controls the computational nuances of the train() method.
trctrl <- trainControl(method = "repeatedcv", number = 10, repeats = 3)
set.seed(3333)
knn_fit <- train(V1 ~., data = training, method = "knn",
trControl=trctrl,
preProcess = c("center", "scale"),
tuneLength = 10)
We are setting 3 parameters of trainControl() method. The “method” parameter holds the details about resampling method. We can set “method” with many values like “boot”, “boot632”, “cv”, “repeatedcv”, “LOOCV”, “LGOCV” etc. For this tutorial, let’s try to use repeatedcv i.e, repeated cross-validation.
The “number” parameter holds the number of resampling iterations. The “repeats ” parameter contains the complete sets of folds to compute for our repeated cross-validation. We are using setting number =10 and repeats =3. This trainControl() methods returns a list. We are going to pass this on our train() method.
Before training our knn classifier, set.seed().
For training knn classifier, train() method should be passed with “method” parameter as “knn”. We are passing our target variable V1. The V1~. denotes a formula for using all attributes in our classifier and V1 as the target variable. The “trControl” parameter should be passed with results from our trianControl() method. The “preProcess” parameter is for preprocessing our training data.
As discussed earlier for our data, preprocessing is a mandatory task. We are passing 2 values in our “preProcess” parameter “center” & “scale”. These two help for centering and scaling the data. After preProcessing these convert our training data with mean value as approximately “0” and standard deviation as “1”. The “tuneLength” parameter holds an integer value. This is for tuning our algorithm.
Trained Knn model result
You can check the result of our train() method. We are saving its results in a knn_fit variable.
> knn_fit k-Nearest Neighbors 125 samples 13 predictor 3 classes: '1', '2', '3' Pre-processing: centered (13), scaled (13) Resampling: Cross-Validated (10 fold, repeated 3 times) Summary of sample sizes: 114, 112, 113, 112, 114, 112, ... Resampling results across tuning parameters: k Accuracy Kappa 5 0.9543790 0.9317929 7 0.9404512 0.9109657 9 0.9379260 0.9073292 11 0.9374598 0.9067419 13 0.9396270 0.9099077 15 0.9482129 0.9225977 17 0.9479604 0.9222815 19 0.9516706 0.9276711 21 0.9597597 0.9401666 23 0.9432678 0.9152521 Accuracy was used to select the optimal model using the largest value. The final value used for the model was k = 21.
Its showing Accuracy and Kappa metrics result for different k value. From the results, it automatically selects best k-value. Here, our training model is choosing k = 21 as its final value.
We can see variation in Accuracy w.r.t K value by plotting these in a graph.
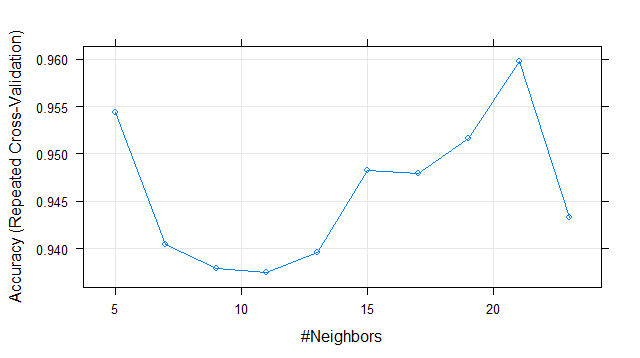
Accuracy vs K-Value
Test Set Prediction
Now, our model is trained with K value as 21. We are ready to predict classes for our test set. We can use predict() method.
> test_pred <- predict(knn_fit, newdata = testing) > test_pred [1] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 3 2 2 2 2 2 2 2 3 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 [40] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 Levels: 1 2 3
caret package provides predict() method for predicting results. We are passing 2 arguments. The first parameter is our trained model and second parameter “newdata” holds our testing data frame. The predict() method returns a list, we are saving it in a test_pred variable.
How Accurately our model is working?
Using confusion matrix, we can print statistics of our results. It shows that our model accuracy for test set is 96.23%.
> confusionMatrix(test_pred, testing$V1 ) Confusion Matrix and Statistics Reference Prediction 1 2 3 1 15 0 0 2 0 22 0 3 0 2 14 Overall Statistics Accuracy : 0.9623 95% CI : (0.8702, 0.9954) No Information Rate : 0.4528 P-Value [Acc > NIR] : 1.208e-15 Kappa : 0.9421 Mcnemar's Test P-Value : NA Statistics by Class: Class: 1 Class: 2 Class: 3 Sensitivity 1.000 0.9167 1.0000 Specificity 1.000 1.0000 0.9487 Pos Pred Value 1.000 1.0000 0.8750 Neg Pred Value 1.000 0.9355 1.0000 Prevalence 0.283 0.4528 0.2642 Detection Rate 0.283 0.4151 0.2642 Detection Prevalence 0.283 0.4151 0.3019 Balanced Accuracy 1.000 0.9583 0.9744
You can download code from our github code repo. It can be accessed from here.
Related Articles To Read
- Introduction to knn algorithm
- Knn algorithm implementation purely in python without any machine learning libraries
- Cancer tumor detection with knn sklearn
- Knn implementation in R without any libraries
References:
- Wine Dataset, Lichman, M. (2013). UCI Machine Learning Repository.
- caret package documentation
Follow us:
FACEBOOK| QUORA |TWITTER| GOOGLE+ | LINKEDIN| REDDIT | FLIPBOARD | MEDIUM | GITHUB
I hope you like this post. If you have any questions, then feel free to comment below. If you want me to write on one particular topic, then do tell it to me in the comments below.
Related Courses:
Do check out unlimited data science courses
| Title & links | Details | What You Will Learn |
| Machine Learning A-Z: Hands-On Python & R In Data Science
|
Course Overall Rating:: 4.6 |
|
| R Programming A-Z: R For Data Science With Real Exercises!
|
Course Overall Rating :: 4.6 |
|
Data Mining with R: Go from Beginner to Advanced! |
Course Overall Rating :: 4.2 |
|







Great article!
Hi tharsy,
Thanks for the compliment.
Happy learning.
confusionMatrix(test_pred, testing$V1)
Returns:
Error: `data` and `reference` should be factors with the same levels.
Hi Las911,
Could you please check the input parameters you are passing to the confusionMatrix function before calling the function?
Can I ask, would it be possible to expand this to demonstrate how to draw a ROC curve and calculate AUC with code? I found this really helpful, I’m just stuck on the very last ROC/AUC part now. I’m looking through forums, but I found this so much easier to understand.
Hi Eva,
Will share with you.
Thanks Sir..It was great helpful.
Hi Bharat Kumar,
We are glad the article helpful to you.
Great and clear write-up. Can you elaborate what “tuneLength” does when fitting the model? Thanks!
Hi Gene Nguyen,
Thanks for your compliment 🙂
Will write an article about tuning models using caret, In which I will explain the usage of tunelength.
Thanks a lot! i was using the class package but it’s very barebones compared with this one. Clearly explained. Thanks!
Hi Jose Banuelos,
Thanks for your compliment.
I used the same data to test my Quantized classifier that is written in GO. https://bitbucket.org/joexdobs/ml-classifier-gesture-recognition It got 96% accuracy on the test data set. This data must be easily classified.
The bat file to run it is ClassifyTestWine.bat I used our file split utility to split the input into a .test.csv and .train.csv file so we had 25 rows in the test set.
You can download the code quantized engine and the test direct from bitbucket. The engine is free on a MIT license.
Question: How do you submit articles to the datasprint site?
It’s Great Joe Ellsworth.
You can find the details about submitting the articles to dataaspirant in the below link.
https://dataaspirant.com/join-us/