Python Packages For Datamining
Home | About | Data scientists Interviews | For beginners | Join us
Python Packages For Datamining

Just because you have a “hammer”, doesn’t mean that every problem you come across will be a “nail”.
The intelligent key thing is when you use the same hammer to solve what ever problem you came across. Like the same way when we intended to solve a datamining problem we will face so many issues but we can solve them by using python in a intelligent way.
In very next post I am going to wet your hands to solve one interesting datamining problem using python programming language. So in this post I am going to explain you about some powerful python weapons( packages )
Before stepping directly into python packages let me clear you a doubt which is rotating in your mind right now. Why python ?
Why Python ?
We all know that python is powerful programming language ,But what does that mean, exactly? What makes python a powerful programming language?
Python is Easy
Universally Python has gained reputation because of its easy learning. The syntax of python programming language is designed to be easily readable. Python has significant popularity in scientific computing. The people working in this field are scientists first, and programmers second.
Python is Efficient
Now a days we are working on bulk amount of data popularly know as BIG DATA. The more data you have to process, the more important it becomes to manage the memory you use. Here python will work very efficiently.
Python is Fast
We all know Python is an interpreted language, we may think that it may be slow but some amazing work has been done over the past years to improve Python’s performance. My point is that if you want to do high-performance computing, Python is a viable option today.
Hope I cleared your doubt “why python?” so let me jump to Python Packages for datamining.
NumPy

About:
NumPy is the fundamental package for scientific computing with Python. It contains among other things.NumPy is an extension to the Python programming language, adding support for large, multi-dimensional arrays and matrices, along with a large library of high-level mathematical functions to operate on these arrays. The ancestor of NumPy, Numeric, was originally created by Jim Hugunin with contributions from several other developers. In 2005, Travis Oliphant created NumPy by incorporating features of the competing Numarray into Numeric, with extensive modifications.
| Original author(s) | Travis Oliphant |
|---|---|
| Developer(s) | Community project |
| Initial release | As Numeric, 1995; as NumPy, 2006 |
| Stable release | 1.9.0 / 7 September 2014 |
| Written in | Python, C |
| Operating system | Cross-platform |
| Type | Technical computing |
| License | BSD-new license |
| Website | www.numpy.org |
Installing numpy:
I strongly believe that python is already installed in your computer, if python is not installed in your computer please install it first.
Installing numpy in linux
Open your terminal and copy this commands
sudo apt-get update
sudo apt-get install python-numpySample numpy code
Sample numpy code for using reshape function
[sourcecode language=”python” wraplines=”false”]
from numpy import *
a = arange(12)
a = a.reshape(3,2,2)
print a
[/sourcecode]
Script output
[[[ 0 1] [ 2 3]] [[ 4 5] [ 6 7]] [[ 8 9] [10 11]]]
SciPy
![]()
About:
SciPy (pronounced “Sigh Pie”) is open-source software for mathematics, science, and engineering. The SciPy library depends on NumPy, which provides convenient and fast N-dimensional array manipulation. The SciPy library is built to work with NumPy arrays, and provides many user-friendly and efficient numerical routines such as routines for numerical integration and optimization. Together, they run on all popular operating systems, are quick to install, and are free of charge. NumPy and SciPy are easy to use, but powerful enough to be depended upon by some of the world’s leading scientists and engineers. If you need to manipulate numbers on a computer and display or publish the results, Scipy is one of the most need one.
| Original author(s) | Travis Oliphant, Pearu Peterson, Eric Jones |
|---|---|
| Developer(s) | Community library project |
| Stable release | 0.14.0 / 3 May 2014 |
| Written in | Python, Fortran, C, C++[1] |
| Operating system | Cross-platform (list) |
| Type | Technical computing |
| License | BSD-new license |
| Website | www.scipy.org |
Installing SciPy in linux
Open your terminal and copy this commands
sudo apt-get update
sudo apt-get install python-scipySample SciPy code
[sourcecode language=”python” wraplines=”false”]
from scipy import special, optimize
f = lambda x: -special.jv(3, x)
sol = optimize.minimize(f, 1.0)
x = linspace(0, 10, 5000)
plot(x, special.jv(3, x), ‘-‘, sol.x, -sol.fun, ‘o’)
savefig(‘plot.png’, dpi=96)
[/sourcecode]
Script output
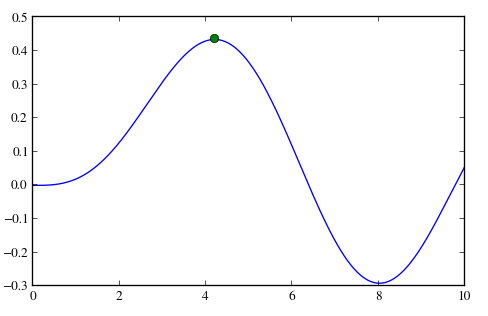
Pandas

About:
Pandas is a Python package providing fast, flexible, and expressive data structures designed to make working with “relational” or “labeled” data both easy and intuitive. It aims to be the fundamental high-level building block for doing practical, real world data analysis in Python. Additionally, it has broader goal of becoming the most powerful and flexible open source data analysis / manipulation tool available in any language. It is already well on its way toward this goal.
Pandas is well suited for many different kinds of data:
- Tabular data with heterogeneously-typed columns, as in an SQL table or Excel spreadsheet.
- Ordered and unordered (not necessarily fixed-frequency) time series data.
- Arbitrary matrix data (homogeneously typed or heterogeneous) with row and column labels.
- Any other form of observational / statistical data sets. The data actually need not be labeled at all to be placed into a pandas data structure.
Installing Pandas in linux
Open your terminal and copy this commands
sudo apt-get update
sudo apt-get install python-pandas
Sample Pandas code
Sample Pandas code about pandas Series
[sourcecode language=”python” wraplines=”false”]
import pandas as pd
values = np.array([2.0, 1.0, 5.0, 0.97, 3.0, 10.0, 0.0599, 8.0])
ser = pd.Series(values)
print ser
[/sourcecode]
Script output
0 2.0000 1 1.0000 2 5.0000 3 0.9700 4 3.0000 5 10.0000 6 0.0599 7 8.0000
Matplotlib
About:
matplotlib is a plotting library for the Python programming language and its NumPy numerical mathematics extension. It provides an object-oriented API for embedding plots into applications using general-purpose GUI toolkits like wxPython, Qt, or GTK+. There is also a procedural “pylab” interface based on a state machine (like OpenGL), designed to closely resemble that of MATLAB. SciPy makes use of matplotlib.
| Original author(s) | John Hunter |
|---|---|
| Developer(s) | Michael Droettboom, et al. |
| Stable release | 1.4.2 (26 October 2014) [±] |
| Written in | Python |
| Operating system | Cross-platform |
| Type | Plotting |
| License | matplotlib license |
| Website | matplotlib.org |
Installing Matplotlib in linux
Open your terminal and copy this commands
sudo apt-get update
sudo apt-get install python-matplotlib
Sample Matplotlib code
Sample Matplotlib code to Create Histograms
[sourcecode language=”python” wraplines=”false”]
import numpy as np
import matplotlib.mlab as mlab
import matplotlib.pyplot as plt
# example data
mu = 100 # mean of distribution
sigma = 15 # standard deviation of distribution
x = mu + sigma * np.random.randn(10000)
num_bins = 50
# the histogram of the data
n, bins, patches = plt.hist(x, num_bins, normed=1, facecolor=’green’, alpha=0.5)
# add a ‘best fit’ line
y = mlab.normpdf(bins, mu, sigma)
plt.plot(bins, y, ‘r–‘)
plt.xlabel(‘Smarts’)
plt.ylabel(‘Probability’)
plt.title(r’Histogram of IQ: $mu=100$, $sigma=15$’)
# Tweak spacing to prevent clipping of ylabel
plt.subplots_adjust(left=0.15)
plt.show()
[/sourcecode]
Script output
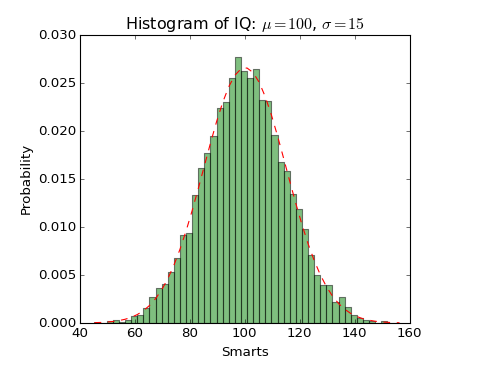
Ipython

IPython is a command shell for interactive computing in multiple programming languages, originally developed for the Python programming language, that offers enhanced introspection, rich media, additional shell syntax, tab completion, and rich history. IPython currently provides the following features:
- Powerful interactive shells (terminal and Qt-based).
- A browser-based notebook with support for code, text, mathematical expressions, inline plots and other rich media.
- Support for interactive data visualization and use of GUI toolkits.
- Flexible, embeddable interpreters to load into one’s own projects.
- Easy to use, high performance tools for parallel computing.
| Original author(s) | Fernando Perez and others |
|---|---|
| Stable release | 2.3 / 1 October 2014 |
| Written in | Python, JavaScript, CSS,HTML |
| Operating system | Cross-platform |
| Type | Shell |
| License | BSD |
| Website | www.ipython.org |
Installing Ipython in linux
Open your terminal and copy this commands
sudo apt-get update
sudo pip install ipythonSample Ipython code
This piece of code is to plot demonstrating the integral as the area under a curve
[sourcecode language=”python” wraplines=”false”]
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.patches import Polygon
def func(x):
return (x – 3) * (x – 5) * (x – 7) + 85
a, b = 2, 9 # integral limits
x = np.linspace(0, 10)
y = func(x)
fig, ax = plt.subplots()
plt.plot(x, y, ‘r’, linewidth=2)
plt.ylim(ymin=0)
# Make the shaded region
ix = np.linspace(a, b)
iy = func(ix)
verts = [(a, 0)] + list(zip(ix, iy)) + [(b, 0)]
poly = Polygon(verts, facecolor=’0.9′, edgecolor=’0.5′)
ax.add_patch(poly)
plt.text(0.5 * (a + b), 30, r"$int_a^b f(x)mathrm{d}x$",
horizontalalignment=’center’, fontsize=20)
plt.figtext(0.9, 0.05, ‘$x$’)
plt.figtext(0.1, 0.9, ‘$y$’)
ax.spines[‘right’].set_visible(False)
ax.spines[‘top’].set_visible(False)
ax.xaxis.set_ticks_position(‘bottom’)
ax.set_xticks((a, b))
ax.set_xticklabels((‘$a$’, ‘$b$’))
ax.set_yticks([])
plt.show()
[/sourcecode]
Script output
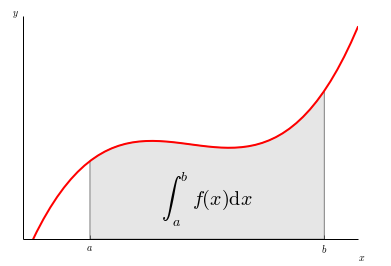
scikit-learn
![]()
The scikit-learn project started as scikits.learn, a Google Summer of Code project by David Cournapeau. Its name stems from the notion that it is a “SciKit” (SciPy Toolkit), a separately-developed and distributed third-party extension to SciPy. The original codebase was later extensively rewritten by other developers. Of the various scikits, scikit-learn as well as scikit-image were described as “well-maintained and popular” in November 2012.
| Original author(s) | David Cournapeau |
|---|---|
| Initial release | June 2007[1] |
| Stable release | 0.15.1 / August 1, 2014[2] |
| Written in | Python, Cython, C andC++ |
| Operating system | Linux, Mac OS X,Microsoft Windows |
| Type | Library for machine learning |
| License | BSD License |
| Website | scikit-learn.org |
Installing Scikit-learn in linux
Open your terminal and copy this commands
sudo apt-get update
sudo apt-get install python-sklearn
Sample Scikit-learn code
[sourcecode language=”python” wraplines=”false”]
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model
# Load the diabetes dataset
diabetes = datasets.load_diabetes()
# Use only one feature
diabetes_X = diabetes.data[:, np.newaxis]
diabetes_X_temp = diabetes_X[:, :, 2]
# Split the data into training/testing sets
diabetes_X_train = diabetes_X_temp[:-20]
diabetes_X_test = diabetes_X_temp[-20:]
# Split the targets into training/testing sets
diabetes_y_train = diabetes.target[:-20]
diabetes_y_test = diabetes.target[-20:]
# Create linear regression object
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(diabetes_X_train, diabetes_y_train)
# The coefficients
print(‘Coefficients: n’, regr.coef_)
# The mean square error
print("Residual sum of squares: %.2f"
% np.mean((regr.predict(diabetes_X_test) – diabetes_y_test) ** 2))
# Explained variance score: 1 is perfect prediction
print(‘Variance score: %.2f’ % regr.score(diabetes_X_test, diabetes_y_test))
# Plot outputs
plt.scatter(diabetes_X_test, diabetes_y_test, color=’black’)
plt.plot(diabetes_X_test, regr.predict(diabetes_X_test), color=’blue’,
linewidth=3)
plt.xticks(())
plt.yticks(())
plt.show()
[/sourcecode]
Script output
Coefficients: [ 938.23786125] Residual sum of squares: 2548.07 Variance score: 0.47

I have explained the packages which we are going to use in coming post to solve some interesting problems.
please leave your comment if i have to add any other python datamining packages to this list
Follow us:
FACEBOOK| QUORA |TWITTER| REDDIT | FLIPBOARD | MEDIUM | GITHUB
I hope you liked today post. If you have any questions then feel free to comment below. If you want me to write on one specific topic then do tell me in the comments below.





Hi good post. I would suggest adding seaborn to this list, it makes figures from matplotlib look a lot better!
Superb..!
Thanks 🙂
i need a help. How to learn about python with orange in data mining concepts. So i need text book name with author.
Hi Rajendiran P
Good to listen your interest in Datamining. you don’t need any Text book just follow Orange Documentation properly. If you want me to write a post on that. please let me know. i am giving Orange Tutorial link here please check with it.
http://www.orange.biolab.si/tutorial/rst/index.html
I like your site and would love to guest post on it!
Be sure to check my site out:
http://programmingforanalysis.com
Thank’s
Reblogged this on Aaron Zeng.
nice site bro
Thank’s
I have tried installation of all the above..but an error has always occoured. So can you make a post of the installation of these for python 3.3 and above.
Try sudo pip install package-name
example: sudo pip install pandas